Foundation models represent a breakthrough in artificial intelligence, being vast deep-learning architectures pre-trained on extensive volumes of general-purpose, unlabeled data. These versatile models are capable of executing various tasks, such as generating images or responding to customer inquiries.
Despite their advanced capabilities, models like ChatGPT and DALL-E can sometimes produce inaccurate or misleading outputs. In critical scenarios—think about a pedestrian nearing a self-driving vehicle—such errors can lead to grave consequences.
To mitigate these risks, a team of researchers from MIT and the MIT-IBM Watson AI Lab has developed a cutting-edge technique aimed at evaluating the reliability of foundation models before they are deployed for specific applications. This approach involves analyzing a collection of similar, yet slightly varied foundation models to gauge how consistently each one interprets the same data input. If the interpretations align, the model can be deemed reliable.
Upon testing, their method outperformed existing state-of-the-art techniques, demonstrating enhanced effectiveness in evaluating the reliability of foundation models across various classification tasks.
This reliability assessment technique can be essential for determining model applicability in specific contexts, eliminating the necessity for tests on real-world datasets. This is particularly advantageous in fields like healthcare, where privacy regulations may restrict data access. Additionally, the method allows for the ranking of models based on their reliability scores, enabling users to select the most appropriate model for their needs.
“All models can be wrong, but those that can recognize their own errors are far more valuable. Quantifying uncertainty or reliability poses a greater challenge for foundation models due to the complexities in comparing their abstract representations,” explains Navid Azizan, the Esther and Harold E. Edgerton Assistant Professor in MIT’s Department of Mechanical Engineering, and a member of the Laboratory for Information and Decision Systems (LIDS). “Our method empowers users to quantify the reliability of representation models for any given data input.”
Alongside lead author Young-Jin Park, a LIDS graduate student, the research team also includes Hao Wang, a research scientist at the MIT-IBM Watson AI Lab, and Shervin Ardeshir, a senior research scientist at Netflix. Their findings are set to be presented at the upcoming Conference on Uncertainty in Artificial Intelligence.
Measuring Model Reliability
Typically, traditional machine learning models are meticulously trained for specific tasks, yielding definitive predictions based on input data. For instance, a model can accurately determine whether an image features a cat or a dog. In these cases, reliability can be assessed by the correctness of the final output.
Conversely, foundation models operate differently—initially pre-trained on general datasets without knowing their eventual applications. Users customize these models for their specific tasks post-training.
Rather than producing definitive categorizations like “cat” or “dog,” these models generate abstract representations for each input. To evaluate their reliability, the researchers employed an ensemble method, training several models that share core attributes but possess slight variations.
“Our approach resembles measuring consensus,” Park notes. “If all models produce consistent representations for a given dataset, we can confidently assert that the model is reliable.”
However, a challenge emerged: how could they effectively compare these abstract representations?
“Since these models output numerical vectors, straightforward comparisons are not feasible,” he added.
To overcome this hurdle, the researchers introduced the concept of neighborhood consistency. They established a collection of reliable reference points to test against the model ensemble. For each model, they examined how the reference points clustered around the model’s representation of a test input.
By analyzing the consistency of these neighboring points, the team could assess the reliability of the models’ outputs.
Aligning Representations for Better Understanding
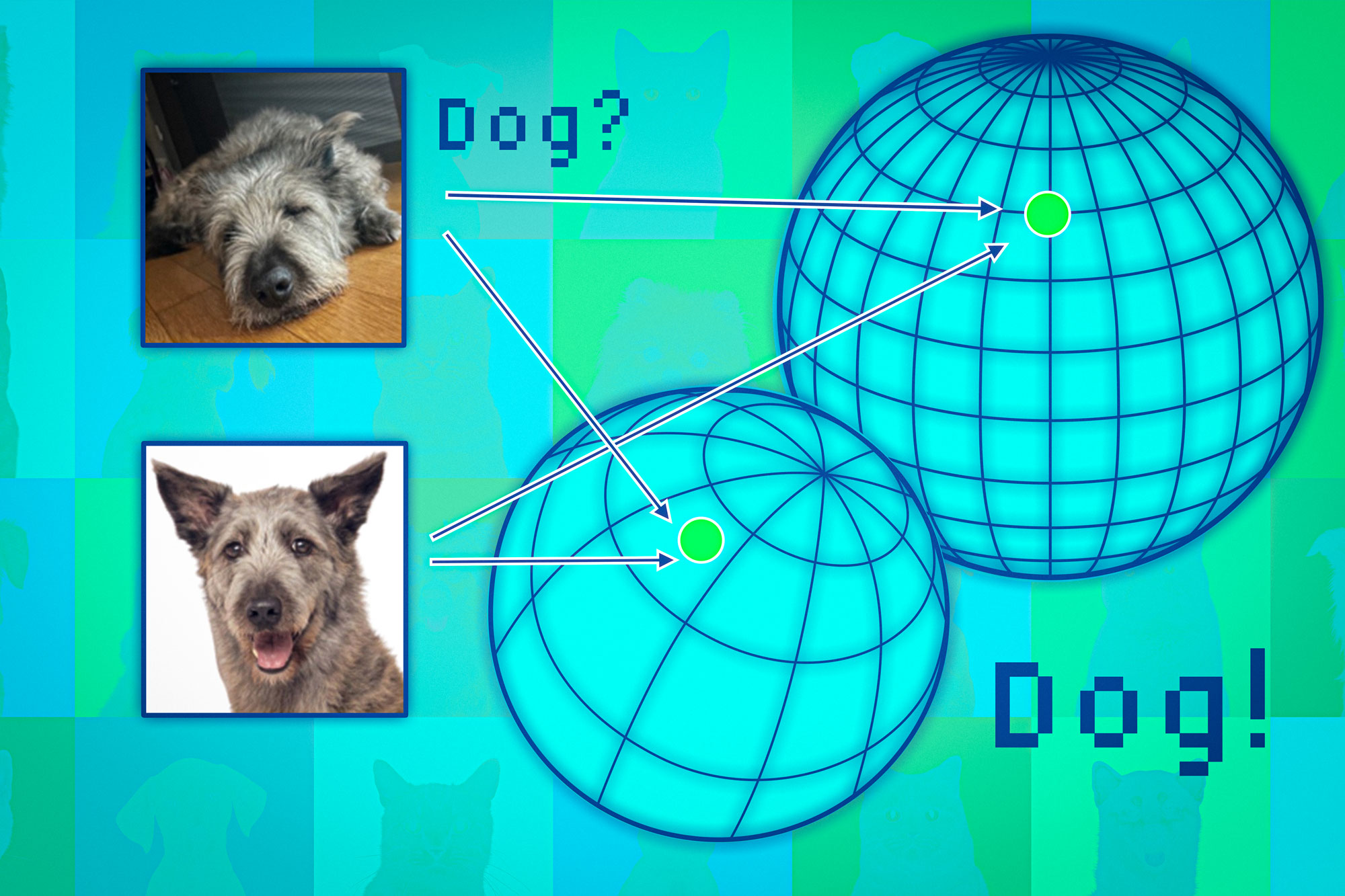
Foundation models convert data points into what’s known as a representation space. Picture this space as a sphere: each model organizes similar data into designated areas—such as clustering images of cats together while separating them from images of dogs.
However, different models can position these groupings differently within their spheres; for instance, one model may place cats in the Southern Hemisphere while another locates them in the Northern Hemisphere.
The researchers utilized neighboring points as anchors to align these spheres, thereby ensuring comparability of respective representations. If a data point exhibits consistency among its neighbors across different models, one can trust the model’s output reliability for that particular input.
Testing this methodology across numerous classification tasks yielded promising results, significantly surpassing baseline models in terms of consistency while remaining resilient against challenging data points that previously confounded other approaches.
Importantly, their technique applies to any input data assessment, allowing for evaluations tailored to specific individuals, such as patients with unique health conditions.
“Even if models exhibit average overall performance, from an individual perspective, the preference lies with the one that caters best to that unique individual,” Wang observes.
Nonetheless, a notable drawback involves the computational intensity required to train an ensemble of foundation models. Future work aims to explore more efficient strategies, perhaps utilizing minor perturbations of a single model.
“Given the trend towards leveraging foundation models for various downstream tasks, such as fine-tuning and retrieval-augmented generation, quantifying uncertainty at the representation level is becoming increasingly crucial yet remains a complex challenge,” states Marco Pavone, an associate professor in Stanford University’s Department of Aeronautics and Astronautics. “This research represents a significant advancement in high-quality uncertainty quantification for embedding models, and I eagerly await future extensions that could streamline the approach for larger foundation models.”
This research has received funding from the MIT-IBM Watson AI Lab, MathWorks, and Amazon.
Photo credit & article inspired by: Massachusetts Institute of Technology


