Imagine cruising through a dimly lit tunnel in an autonomous vehicle, blissfully unaware that a collision has brought traffic to a halt just ahead. In typical scenarios, you would have to wait for the vehicle in front to signal the need to brake. But what if your vehicle could anticipate and respond even earlier by “seeing” past the car ahead?
Innovative researchers from MIT and Meta have introduced a groundbreaking computer vision technique designed to achieve just that for autonomous vehicles.
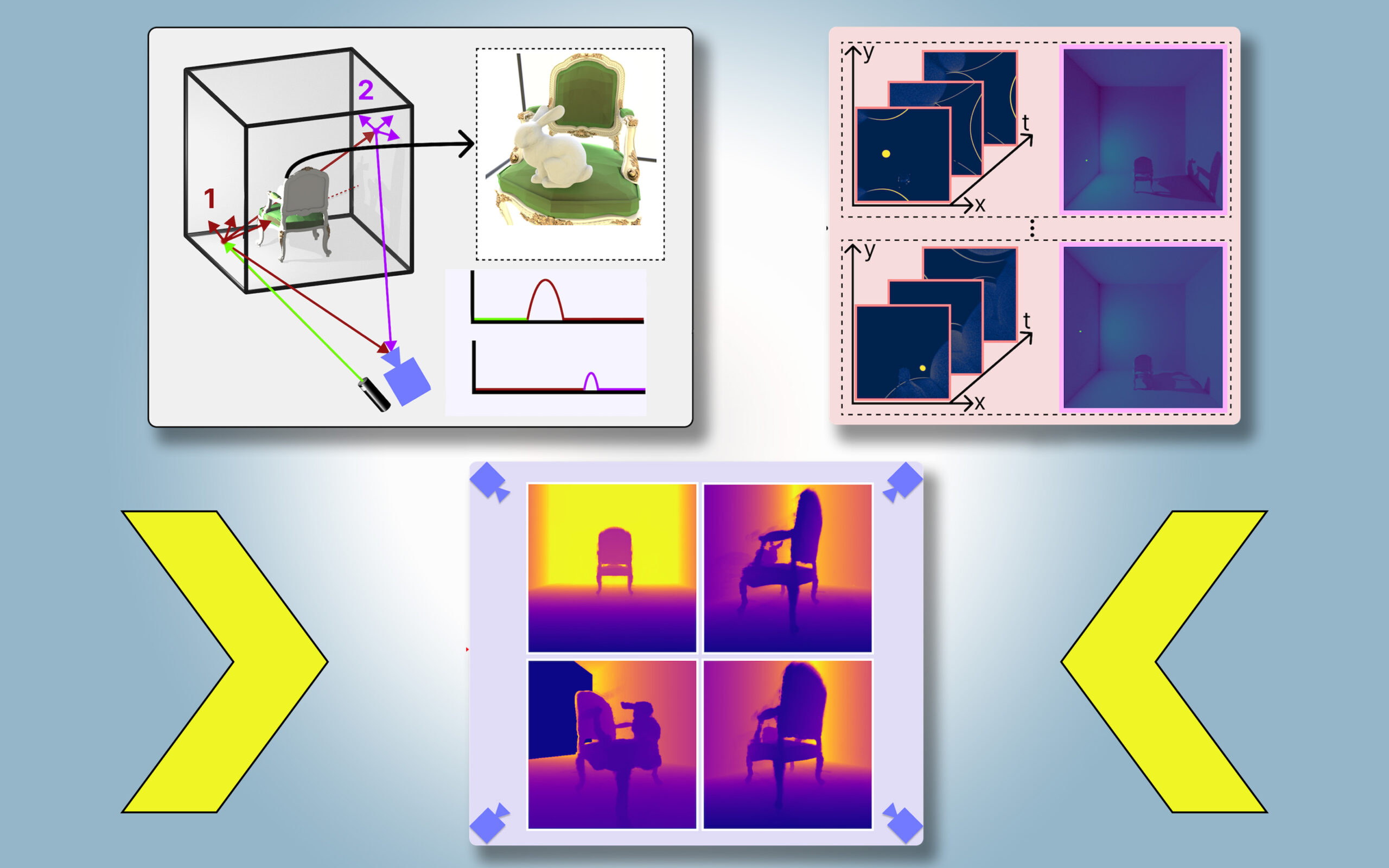
This new approach, dubbed PlatoNeRF, harnesses images captured from a single camera to create precise, three-dimensional models of scenes, including areas that may be hidden from direct view. Utilizing shadows as a clue, this technology elucidates the layout of obstructed spaces.
The name PlatoNeRF draws inspiration from the allegory of the cave, a concept presented in Plato’s Republic, where prisoners, confined to a cave, interpret reality based solely on shadows projected on the wall.
By integrating lidar (light detection and ranging) technology with advanced machine learning, PlatoNeRF enhances the accuracy of 3D geometry reconstructions, outperforming prior AI methodologies. Moreover, it excels at reconstructing scenes where shadows might be challenging to discern due to high ambient light or dark backgrounds.
Beyond boosting the safety of self-driving cars, this technology could revolutionize augmented reality (AR) and virtual reality (VR) headsets by enabling users to model room geometries without the need to navigate physically. It also stands to aid warehouse robots in efficiently locating items amidst clutter.
“Our principal idea was to merge two previously distinct approaches—multibounce lidar and machine learning. This synergy opens up numerous possibilities and combines their strengths,” explains Tzofi Klinghoffer, an MIT graduate student in media arts and sciences and the study’s lead author, in a recent paper on PlatoNeRF.
Klinghoffer collaborated with his advisor, Ramesh Raskar, an associate professor of media arts and sciences leading the Camera Culture Group at MIT, alongside senior author Rakesh Ranjan from Meta Reality Labs. Their research will be shared at the upcoming Conference on Computer Vision and Pattern Recognition.
Illuminating the Challenge
Reconstructing a complete 3D scene from a single camera angle poses a significant challenge. Some existing machine-learning strategies utilize generative AI models that attempt to predict unseen areas, yet they can produce inaccuracies, generating nonexistent objects. Alternatively, methods that assess hidden shapes from shadows in color images often struggle when shadows are faint.
PlatoNeRF builds upon these existing paradigms by implementing a novel sensing technique called single-photon lidar. This technology utilizes emitted light pulses and measures how long they take to return, creating a detailed mapping of the environment. Thanks to its ability to detect individual photons, single-photon lidar yields high-resolution data.
The researchers employ single-photon lidar to shine light on specific points in a scene. Some light reflects directly back, while most scatters off surrounding objects before returning to the detector. PlatoNeRF capitalizes on these secondary light bounces.
By monitoring the time it takes for light to bounce back twice, PlatoNeRF assembles additional scene information, including depth and shadow details. The system tracks secondary rays—those that bounce off the target onto other scene points—to pinpoint areas shrouded in shadow, allowing the software to infer the shapes of concealed objects.
The lidar system sequentially illuminates 16 points, gathering multiple images to recreate the entire three-dimensional scene.
“With each point we illuminate, new shadows are created, leading to a multitude of light rays that effectively map out occluded areas unseen by the naked eye,” Klinghoffer elaborates.
A Synergistic Approach
A critical element of PlatoNeRF lies in the integration of multibounce lidar technology with a specific type of machine learning model known as a neural radiance field (NeRF). A NeRF encodes a scene’s geometry within a neural network’s parameters, enabling the model to extrapolate and estimate novel scene viewpoints effectively.
This interpolation capability significantly enhances the accuracy of scene reconstructions when combined with multibounce lidar, Klinghoffer asserts.
“The biggest challenge was understanding how to merge these technologies effectively, considering the physics of light behavior in multibounce lidar and modeling it within a machine-learning context,” he recounts.
In tests, PlatoNeRF surpassed two standard methods—one relying solely on lidar and another strictly using a NeRF with a color image—particularly excelling with lower-resolution lidar sensors. This advantage could facilitate real-world deployment, especially where commercial devices often utilize less powerful sensors.
“Fifteen years ago, our group pioneered the first ‘corner-seeing’ camera technology by leveraging the same light-bounce techniques. Since then, lidar has gained mainstream traction, leading to our ongoing work on fog-penetrating cameras. This latest endeavor utilizes just two light bounces, achieving a high signal-to-noise ratio and impressive 3D reconstruction accuracy,” Raskar emphasizes.
Moving forward, the team hopes to explore tracking more than two light bounces to further enhance scene reconstruction capabilities. They also plan to integrate deeper machine learning techniques and harmonize PlatoNeRF with color image data for texture information capture.
“While shadow analysis in camera imagery has long been researched for 3D reconstruction, this work reapproaches the challenge through the lens of lidar, showcasing significant advancements in accurately reconstructing concealed geometries. This study exemplifies how intelligent algorithms can yield remarkable functionalities by synergizing simple sensors—like the compact lidar systems we now often carry with us,” remarks David Lindell, an assistant professor within the Department of Computer Science at the University of Toronto, who was not involved in this study.
Photo credit & article inspired by: Massachusetts Institute of Technology