Picture this: you’re tasked with tidying a cluttered kitchen, starting with a counter overflowing with various sauce packets. If your goal is simply to clean the counter, you might gather all the packets in one swoop. But if you want to separate the mustard packets first, your approach becomes more discerning, focusing on specific types. And if you’re on the hunt for a particular brand, such as Grey Poupon, finding it would require an even more meticulous search.
In an exciting breakthrough, engineers at MIT have created a method that empowers robots to make smart, relevant decisions akin to our own intuitions.
Introducing Clio, a pioneering approach that allows robots to discern the critical elements of a scene based on assigned tasks. With Clio, robots receive a list of tasks articulated in natural language, enabling them to adapt their perception and “remember” only the pertinent parts of their surroundings.
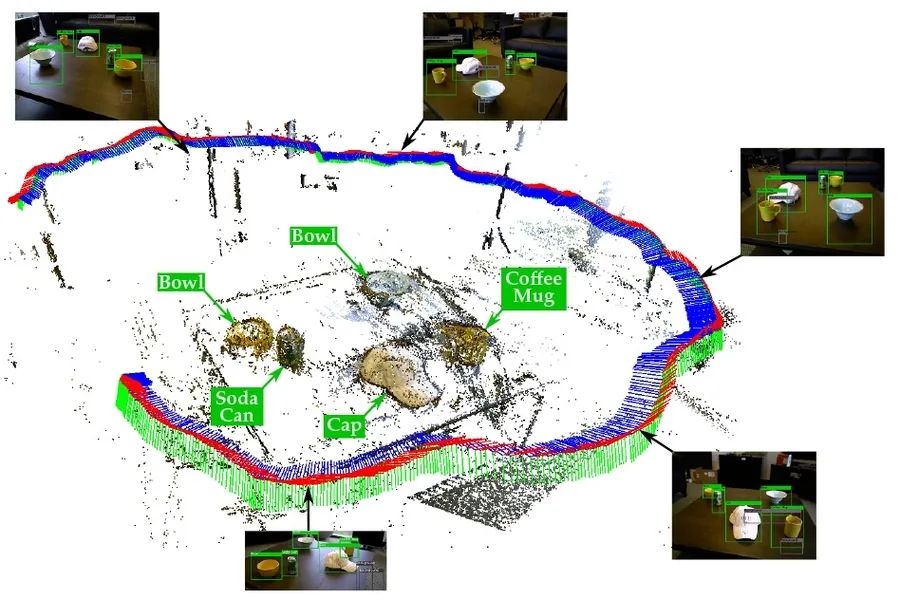
The research team conducted real-world experiments from a cluttered cubicle to an expansive five-story building on the MIT campus. By utilizing Clio, they could automatically break down scenes at varying levels of detail according to natural-language prompts like “move rack of magazines” or “retrieve first aid kit.”
Clio was also effectively implemented in real-time on a quadruped robot during its exploration of an office space. This setup allowed the robot to focus solely on elements relevant to specific tasks (like fetching a dog toy while disregarding extraneous office supplies), facilitating a more efficient retrieval process.
Named after the Greek muse of history, Clio’s function is to identify and retain only what is necessary for a particular mission. The researchers foresee its applications extending far beyond the lab, imagining Clio’s use in diverse scenarios where robots need to quickly evaluate and understand their surroundings in correlation with their tasks.
“While our primary motivation for this work lies in search and rescue applications, Clio holds promise for domestic robots and those working alongside humans on factory floors,” shares Luca Carlone, an associate professor in MIT’s Department of Aeronautics and Astronautics. He also leads the Laboratory for Information and Decision Systems and the MIT SPARK Laboratory. “Ultimately, it’s about enhancing a robot’s understanding of its environment to execute its mission effectively.”
The research team presents their findings in an article published in the journal Robotics and Automation Letters. Co-authors include members from the SPARK Laboratory—Dominic Maggio, Yun Chang, Nathan Hughes, and Lukas Schmid—and colleagues from MIT Lincoln Laboratory, comprising Matthew Trang, Dan Griffith, Carlyn Dougherty, and Eric Cristofalo.
Expanding Horizons
Significant advancements in computer vision and natural language processing have enabled robots to recognize objects in their environment. However, until recently, robotic capabilities were restricted to “closed-set” scenarios, where they operated within carefully controlled settings with a limited number of recognizable objects.
Recently, a shift towards an “open” strategy has surfaced, allowing robots to identify objects in more dynamic, real-world conditions. In this realm of open-set recognition, researchers have employed deep-learning technologies to create neural networks capable of analyzing billions of images along with their associated textual data, such as social media announcements featuring pets.
This training allows a neural network to spot specific characteristics of objects, like dogs, and utilize that knowledge to recognize similar entities in previously unseen environments. Nevertheless, challenges persist in effectively parsing scenes in a way that aligns with the tasks at hand.
“Traditional methodologies often impose a fixed granularity level for grouping scene segments into singular ‘objects,’” explains Maggio. “However, the definition of an ‘object’ truly hinges on the robot’s objectives. If this granularity is predetermined without considering task relevance, it can lead to inefficient mapping.”
Navigating the Information Bottleneck
The MIT team aimed to enhance robots’ capabilities through Clio, allowing them to interpret their environments with task-adjustable granularities.
For example, if the objective is to relocate an entire stack of books to a shelf, the system should recognize that the whole stack represents the task-relevant object. Conversely, if the task specifies moving only a green book from the stack, Clio must isolate that single book while dismissing the other items in the scene.
The researchers’ strategy merges cutting-edge computer vision with advanced large language models, linking neural networks across millions of open-source images and semantic text. They also utilize mapping techniques to divide images into smaller segments, passing them through a neural network to establish semantic similarities. Furthermore, by applying a classical information theory concept known as the “information bottleneck,” they manage to efficiently compress image segments, preserving those most applicable to a specific task.
“Imagine a scene with several books, and the mission is to retrieve just the green book. We funnel all this contextual information through the bottleneck to emerge with segments that accurately represent the green book,” Maggio elaborates. “Unrelated segments are clustered and can be discarded, resulting in a precise object representation necessary for executing the task.”
The team successfully tested Clio across various real-world environments.
“To illustrate Clio’s efficacy, we ran an experiment in my own apartment, which I hadn’t prepped for cleanliness,” shares Maggio. “We generated a list of natural-language tasks, such as ‘relocate the pile of clothes,’ then applied Clio to process images of the clutter.” In these situations, Clio adeptly segmented the apartment scenes and utilized the Information Bottleneck method to pinpoint relevant segments that constituted the pile of clothes.
Clio’s capabilities were further demonstrated with Boston Dynamics’ quadruped robot, Spot. Given a task list, as Spot roamed an office building, Clio operated in real-time on the onboard computer, identifying and mapping relevant task-related segments in its visual feed. This process culminated in a focused overlay map indicating just the target objects, which the robot subsequently approached to fulfill its assigned tasks.
“Executing Clio in real-time represented a significant milestone for our team,” Maggio adds. “Previous approaches often took several hours to complete similar tasks.”
Looking ahead, the team aims to enhance Clio’s ability to tackle higher-level tasks and harness recent developments in photorealistic scene representation.
“Currently, we assign Clio relatively straightforward tasks, like ‘locate a deck of cards,’” Maggio concludes. “In search and rescue scenarios, we’ll need to provide more complex directives, such as ‘find survivors’ or ‘restore power.’ Our aim is to develop a more human-like comprehension for managing intricate tasks.”
This research received support from the U.S. National Science Foundation, the Swiss National Science Foundation, MIT Lincoln Laboratory, the U.S. Office of Naval Research, and the U.S. Army Research Lab Distributed and Collaborative Intelligent Systems and Technology Collaborative Research Alliance.
Photo credit & article inspired by: Massachusetts Institute of Technology