You’ve probably heard the saying that a picture is worth a thousand words. But what about a large language model (LLM) that has never encountered an image before? Can it truly understand visual concepts? Surprisingly, research indicates that text-only trained language models possess a remarkable comprehension of the visual world.
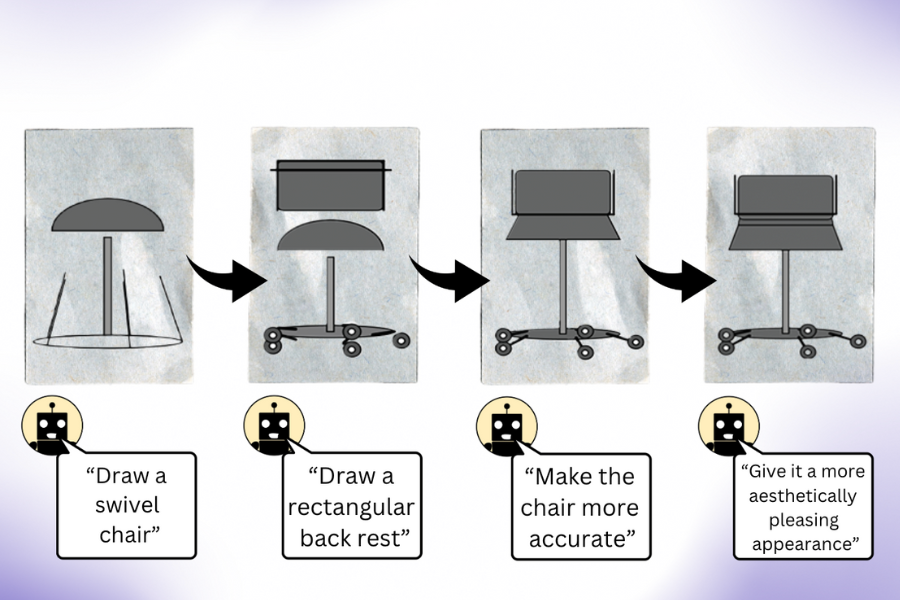
Researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) discovered that these language models can generate intricate image-rendering code, enabling them to create complex scenes filled with captivating objects and compositions. Significantly, even when their initial attempts fall short, LLMs demonstrate the ability to refine and enhance their generated images. When prompted to self-correct their image-rendering code for various visuals, these models improved their simplistic clipart drawings with each iteration.
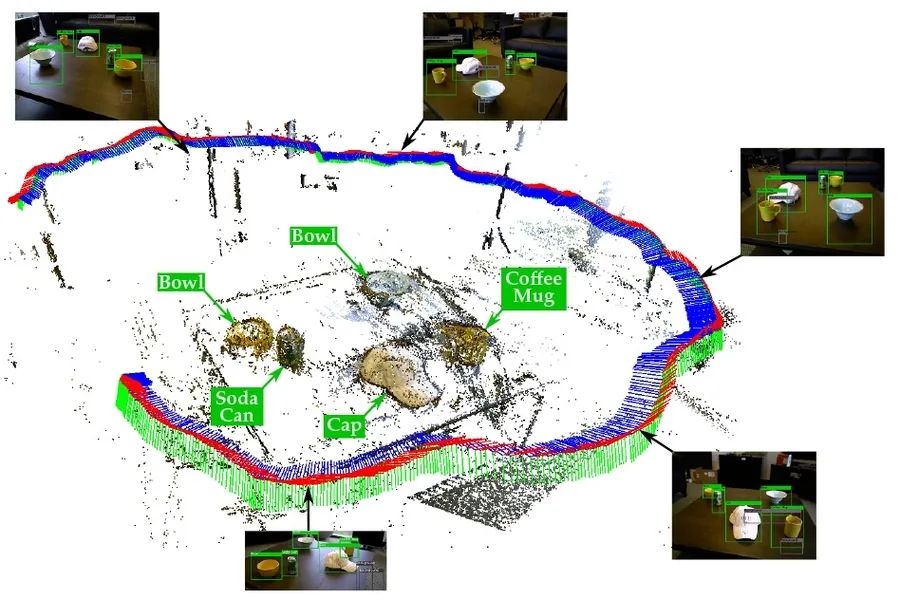
The visual insights of LLMs stem from their ability to interpret concepts like shapes and colors as conveyed in text across the internet. Consider an example where a user instructs the model to “draw a parrot in the jungle.” The LLM taps into its vast reservoir of prior descriptions to generate a coherent image. To evaluate the extent of visual understanding in LLMs, the CSAIL team devised a “vision checkup” using their “Visual Aptitude Dataset,” where they tested the models on their ability to draw, recognize, and self-correct various visual concepts. The researchers then trained a computer vision system using the final drafts of these illustrations to identify items within real photographs.
“We essentially train a vision system without directly using any visual data,” says Tamar Rott Shaham, co-lead author of the study and an MIT electrical engineering and computer science (EECS) postdoc at CSAIL. “Our methodology involved querying language models to write image-rendering codes, which provided the data for the vision system to evaluate natural images. We were motivated by how visual ideas can be expressed through different mediums, like text. LLMs utilize code as a bridge between language and visual representation.”
To create this dataset, the researchers prompted the models to generate code for various shapes, objects, and scenes. The code was then compiled to produce simple digital illustrations, such as a lineup of bicycles, demonstrating that the LLMs adeptly understand spatial relationships. In another case, the model creatively combined concepts to illustrate a car-shaped cake, showcasing its innovative potential. Furthermore, the model generated a radiant light bulb, reflecting its ability to conceptualize visual effects.
“Our findings reveal that when users request an image from an LLM (even one without multimodal pre-training), it possesses a deeper understanding than it may initially demonstrate,” explains Pratyusha Sharma, co-lead author and EECS PhD student at CSAIL. “For instance, if you ask the model to draw a chair, it draws upon extensive knowledge about that furniture piece, which it can refine upon repeated queries. Remarkably, the model can iteratively enhance its drawings by improving its rendering code significantly.”
The compiled illustrations were then employed to train a computer vision system capable of recognizing objects within actual photographs, despite never having encountered a real image. Utilizing synthetic data derived solely from text-based generation, this system surpassed other procedurally generated image datasets trained with genuine photos.
The CSAIL team posits that harnessing the latent visual understanding of LLMs alongside the artistic capabilities of models like diffusion systems could yield superior results. Current tools such as Midjourney may struggle with fine details, often falling short when users request specific adjustments like reducing the number of cars in an image or repositioning an object. If an LLM sketches the requested changes beforehand, the resulting modifications could be far more satisfactory.
Interestingly, Rott Shaham and Sharma noted that LLMs occasionally fail to identify the same concepts they can illustrate accurately. This issue became evident when the models misidentified human-generated representations of images within the dataset, likely due to the varied visual interpretations encountered.
Even though the models faced challenges in abstract visual comprehension, they displayed creativity by drawing the same concepts differently each time. For example, when asked to illustrate strawberries or arcades multiple times, the LLMs produced images from diverse angles and with varying shapes and colors, suggesting the possibility that these models possess a form of mental imagery of the visual concepts—not merely recalling prior examples.
The CSAIL team envisions this process as a foundational approach for assessing how effectively generative AI models can train a computer vision system. Moreover, they plan to broaden the range of tasks assigned to language models. Although the researchers do not have access to the training dataset used for the LLMs involved in their study, thus complicating their exploration of the source of visual knowledge, they aim to improve vision modeling by enabling direct interaction with language models.
Sharma and Rott Shaham are co-authors of the paper alongside former CSAIL member Stephanie Fu ’22, MNG ’23, and EECS PhD students Manel Baradad, Adrián Rodríguez-Muñoz ’22, and Shivam Duggal, along with MIT professors Phillip Isola and Antonio Torralba. Their research received support from grants provided by the MIT-IBM Watson AI Lab, LaCaixa Fellowship, Zuckerman STEM Leadership Program, and Viterbi Fellowship. The paper is set to be presented at the IEEE/CVF Computer Vision and Pattern Recognition Conference.
Photo credit & article inspired by: Massachusetts Institute of Technology